


Menyulap Kata Menjadi Bentuk Dasar: Panduan Lengkap Stemming dan Lemmatization dalam NLP
Dalam dunia Natural Language Processing (NLP), memahami kata bukan hanya soal membaca teks, tetapi juga mengenali makna dasar dari kata tersebut. Di sinilah stemming dan lemmatization berperan. Kedua teknik ini membantu komputer menyederhanakan kata-kata ke bentuk dasarnya sehingga memudahkan analisis, pemrosesan, dan pemahaman bahasa manusia. Artikel ini akan membahas perbedaan, metode, serta aplikasi praktis dari stemming dan lemmatization.
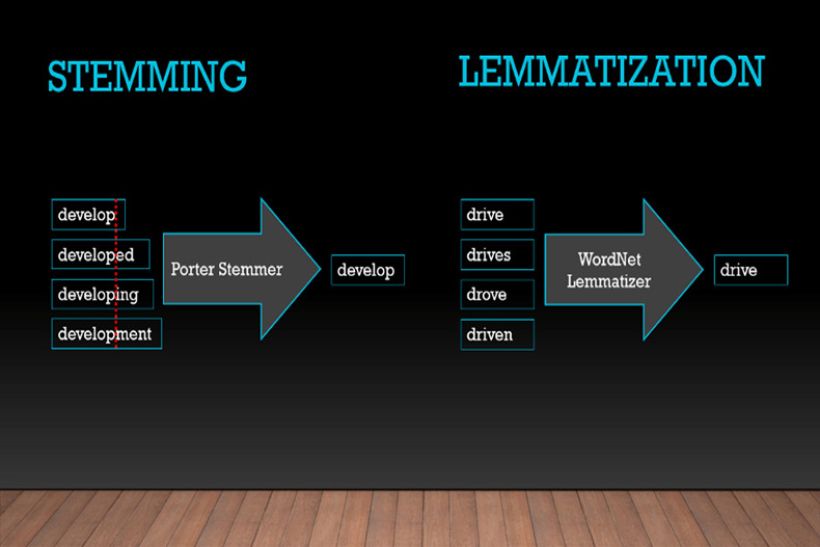
Apa itu Stemming dan Lemmatization?
Secara sederhana, stemming adalah proses memotong atau memangkas kata menjadi bentuk dasarnya (stem) dengan aturan tertentu, tanpa memperhatikan apakah kata hasilnya masih memiliki makna yang tepat. Misalnya, kata “membaca”, “membacakan”, dan “pembaca” mungkin semuanya dipangkas menjadi “baca”.
Sementara itu, lemmatization adalah proses mengubah kata menjadi bentuk dasarnya yang dikenal secara linguistik, atau disebut lemma. Lemmatization lebih cermat karena mempertimbangkan konteks dan tata bahasa. Contohnya, kata “better” akan dikembalikan menjadi “good”, bukan sekadar memotong akhiran.
Dengan kata lain, stemming lebih cepat dan sederhana, sementara lemmatization lebih akurat dan linguistik-aware.
Mengapa Stemming dan Lemmatization Penting?
Bahasa manusia penuh variasi. Kata yang memiliki makna sama bisa muncul dalam banyak bentuk, misalnya:
-
“berlari”, “lari-lari”, “pelari”
-
“menulis”, “menuliskan”, “penulis”
Tanpa menyederhanakan kata-kata ini, sistem NLP akan menganggap setiap bentuk kata sebagai entitas berbeda, yang dapat menurunkan akurasi analisis. Stemming dan lemmatization membantu:
-
Mengurangi dimensi data – Dengan menggabungkan variasi kata menjadi bentuk dasar, jumlah kata unik dalam dataset berkurang, sehingga pemrosesan lebih efisien.
-
Meningkatkan akurasi model NLP – Misalnya dalam klasifikasi teks atau analisis sentimen, model dapat mengenali pola kata yang sama meskipun bentuknya berbeda.
-
Memudahkan pencarian informasi – Sistem pencarian bisa menemukan dokumen yang relevan walaupun pengguna menggunakan kata yang berbeda dari teks asli.
Perbedaan Stemming dan Lemmatization
| Aspek | Stemming | Lemmatization |
|---|---|---|
| Tujuan | Memotong kata menjadi bentuk dasar | Mengubah kata menjadi bentuk lemma linguistik yang benar |
| Akurasi | Kurang akurat, kadang menghasilkan kata tidak bermakna | Lebih akurat, mempertimbangkan konteks |
| Kecepatan | Cepat, sederhana | Lebih lambat, membutuhkan kamus atau analisis morfologi |
| Contoh | “membaca” → “baca”, “menulis” → “tulis” | “better” → “good”, “running” → “run” |
Metode Stemming yang Populer
-
Porter Stemmer
Algoritma klasik yang memotong akhiran kata bahasa Inggris seperti -ing, -ed, dan -s. Misalnya, “playing” menjadi “play”. -
Lancaster Stemmer
Lebih agresif daripada Porter, kadang menghasilkan kata yang terlalu dipangkas. Misalnya, “compute” dan “computer” mungkin menjadi bentuk sama, “comput”. -
Snowball Stemmer
Versi yang lebih modern dari Porter, mendukung beberapa bahasa dan memberikan keseimbangan antara agresivitas dan akurasi.
Metode Lemmatization yang Populer
Lemmatization biasanya membutuhkan kamus atau WordNet, seperti dalam Python library NLTK. Misalnya:
-
Kata: “was”
-
Lemma: “be”
Lemmatization mempertimbangkan kategori kata (part-of-speech), sehingga lebih tepat daripada stemming dalam analisis teks yang membutuhkan akurasi tinggi.
Penerapan Stemming dan Lemmatization
-
Analisis Sentimen
Dalam media sosial atau review produk, kata yang bervariasi seperti “menyenangkan”, “menyenangkan sekali”, dan “senang” bisa disederhanakan agar model mengenali pola emosi positif. -
Pencarian dan Mesin Rekomendasi
Mesin pencari seperti Google atau platform e-commerce menggunakan stemming atau lemmatization agar pencarian menjadi lebih relevan, misalnya “menulis buku” bisa menemukan artikel berjudul “penulisan buku”. -
Text Classification
Dalam klasifikasi email spam atau kategori berita, menyederhanakan kata membantu algoritma machine learning mengenali pola tanpa terganggu variasi kata.
Tantangan Stemming dan Lemmatization
-
Bahasa non-Inggris: Beberapa bahasa seperti bahasa Indonesia, Arab, atau Jepang memiliki struktur kata kompleks yang membuat stemming dan lemmatization lebih sulit.
-
Ambiguitas kata: Kata yang sama bisa memiliki makna berbeda tergantung konteks, misalnya “bank” (sungai vs institusi keuangan). Lemmatization harus mempertimbangkan konteks agar tidak salah.
-
Slang dan bahasa gaul: Media sosial sering menggunakan kata tidak baku, sehingga memerlukan preprocessing tambahan sebelum stemming atau lemmatization.
Stemming dan lemmatization adalah dua teknik penting dalam NLP yang memungkinkan komputer memahami bahasa manusia lebih baik. Stemming cepat dan sederhana, cocok untuk dataset besar, sedangkan lemmatization lebih akurat dan linguistik-aware. Dengan menerapkan teknik ini, sistem NLP dapat meningkatkan efisiensi, akurasi, dan relevansi dalam berbagai aplikasi, mulai dari pencarian informasi hingga analisis sentimen.
Mempelajari stemming dan lemmatization adalah langkah awal yang krusial bagi siapa pun yang ingin menguasai NLP. Dengan memahami bagaimana kata-kata bisa disederhanakan tanpa kehilangan makna, kita membuka pintu menuju pemrosesan bahasa yang lebih cerdas dan interaksi manusia-mesin yang lebih alami.